版本:v2.9.0
调度策略
摘要
当前在一个拥有许多 GPU 节点的集群中,节点在做调度决策时没有进行 binpack 或 spread,使用 vGPU 时 GPU 卡也没有进行 binpack 或 spread。
提案
我们在配置中添加 node-scheduler-policy 和 gpu-scheduler-policy,然后调度器可以使用此策略实现节点 binpack 或 spread 或 GPU binpack 或 spread。用户可以设置 Pod 注释来更改此默认策略,使用 hami.io/node-scheduler-policy 和 hami.io/gpu-scheduler-policy 来覆盖调度器配置。
用户故事
这是一个 GPU 集群,拥有两个节点,以下故事以此集群为前提。
故事 1
节点 binpack,尽可能使用一个节点的 GPU 卡,例如:
-
集群资源:
- 节点 1:GPU 拥有 4 个 GPU 设备
- 节点 2:GPU 拥有 4 个 GPU 设备
-
请求:
- pod1:使用 1 个 GPU
- pod2:使用 1 个 GPU
-
调度结果:
- pod1:调度到节点 1
- pod2:调度到节点 1
故事 2
节点 spread,尽可能使用来自不同节点的 GPU 卡,例如:
-
集群资源:
- 节点 1:GPU 拥有 4 个 GPU 设备
- 节点 2:GPU 拥有 4 个 GPU 设备
-
请求:
- pod1:使用 1 个 GPU
- pod2:使用 1 个 GPU
-
调度结果:
- pod1:调度到节点 1
- pod2:调度到节点 2
故事 3
GPU binpack,尽可能使用同一个 GPU 卡,例如:
-
集群资源:
- 节点 1:GPU 拥有 4 个 GPU 设备,它们是 GPU1, GPU2, GPU3, GPU4
-
请求:
- pod1:使用 1 个 GPU,gpucore 是 20%,gpumem-percentage 是 20%
- pod2:使用 1 个 GPU,gpucore 是 20%,gpumem-percentage 是 20%
-
调度结果:
- pod1:调度到节点 1,选择 GPU1 这个设备
- pod2:调度到节点 1,选择 GPU1 这个设备
故事 4
GPU spread,尽可能使用不同的 GPU 卡,例如:
-
集群资源:
- 节点 1:GPU 拥有 4 个 GPU 设备,它们是 GPU1, GPU2, GPU3, GPU4
-
请求:
- pod1:使用 1 个 GPU,gpucore 是 20%,gpumem-percentage 是 20%
- pod2:使用 1 个 GPU,gpucore 是 20%,gpumem-percentage 是 20%
-
调度结果:
- pod1:调度到节点 1,选择 GPU1 这个设备
- pod2:调度到节点 1,选择 GPU2 这个设备
设计细节
Node-scheduler-policy
Binpack
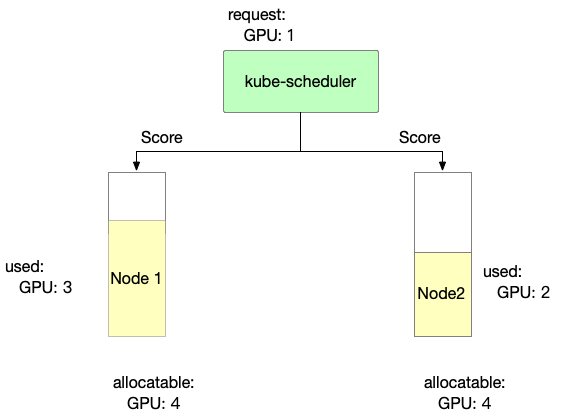
Binpack 主要考虑节点资源使用情况。使用越满,得分越高。
score: ((request + used) / allocatable) * 10
- 节点 1 的 Binpack 评分信息如下
Node1 score: ((1+3)/4) * 10= 10
- 节点 2 的 Binpack 评分信息如下
Node2 score: ((1+2)/4) * 10= 7.5
因此,在 Binpack 策略中我们可以选择 Node1。
Spread
Spread 主要考虑节点资源使用情况。使用越少,得分越高。
score: ((request + used) / allocatable) * 10
- 节点 1 的 Spread 评分信息如下
Node1 score: ((1+3)/4) * 10= 10
- 节点 2 的 Spread 评分信息如下
Node2 score: ((1+2)/4) * 10= 7.5
因此,在 Spread 策略中我们可以选择 Node2。
GPU-scheduler-policy
Binpack
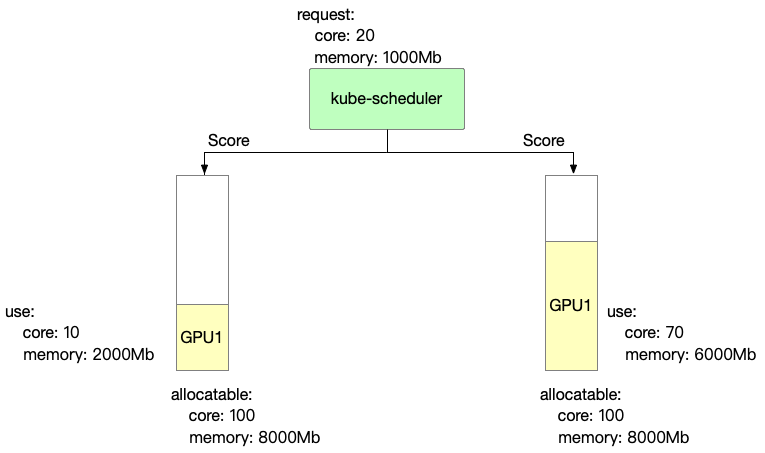
Binpack 主要关注每张卡的计算能力和显存使用情况。使用越多,得分越高。
score: ((request.core + used.core) / allocatable.core + (request.mem + used.mem) / allocatable.mem)) * 10
- GPU1 的 Binpack 评分信息如下
GPU1 Score: ((20+10)/100 + (1000+2000)/8000)) * 10 = 6.75
- GPU2 的 Binpack 评分信息如下
GPU2 Score: ((20+70)/100 + (1000+6000)/8000)) * 10 = 17.75
因此,在 Binpack 策略中我们可以选择 GPU2。
Spread
Spread 主要关注每张卡的计算能力和显存使用情况。使用越少,得分越高。
score: ((request.core + used.core) / allocatable.core + (request.mem + used.mem) / allocatable.mem)) * 10
- GPU1 的 Spread 评分信息如下
GPU1 Score: ((20+10)/100 + (1000+2000)/8000)) * 10 = 6.75
- GPU2 的 Spread 评分信息如下
GPU2 Score: ((20+70)/100 + (1000+6000)/8000)) * 10 = 17.75
因此,在 Spread 策略中我们可以选择 GPU1。
