HAMi 亮相 KubeCon + CloudNativeCon India 2026:将 GPU 共享带给社区
2026 年 6 月 18-19 日,KubeCon + CloudNativeCon India 2026 在印度孟买举行,来自云原生生态的实践者、平台工程师、AI 基础设施团队和开源贡献者齐聚一堂。随着 AI 成为本届大会最重要的主题之一,HAMi 展示了 Kubernetes 原生 GPU 共享如何帮助组织提升加速器利用率,同时保持工作负载隔离和运维灵活性。
从开场 Keynote 到展台现场演示,再到与工程团队的技术讨论,本次活动凸显了一个越来越明确的行业关注点:让昂贵的 GPU 基础设施真正适用于多租户 AI 工作负载。
AI 基础设施成为大会焦点
本届大会一开始就高度聚焦 AI 基础设施。在开场 Keynote 中,Chris Aniszczyk 强调,云原生技术正在成为下一代 AI 平台的基础。
HAMi 在 KubeCon India 的亮相正是对这一趋势的直接回应:通过现场演示,展示 Kubernetes 如何在多个团队和推理工作负载之间共享 GPU 资源,而不必为每个工作负载分配一整张 GPU 或一套独立集群。
Keynote Demo:Kubernetes 上的多租户 AI 推理

在 Saiyam Pathak 的 Keynote 中,HAMi 支撑了一场展示 GPU 共享能力的现场演示。
演示架构包括:
- 运行 Kubernetes 控制平面的 MacBook
- 作为 GPU 工作节点的 NVIDIA DGX Spark
- 用于租户隔离的 vCluster
- 用于细粒度 GPU 分配的 HAMi
- 多个 AI 推理工作负载同时运行在共享 GPU 上
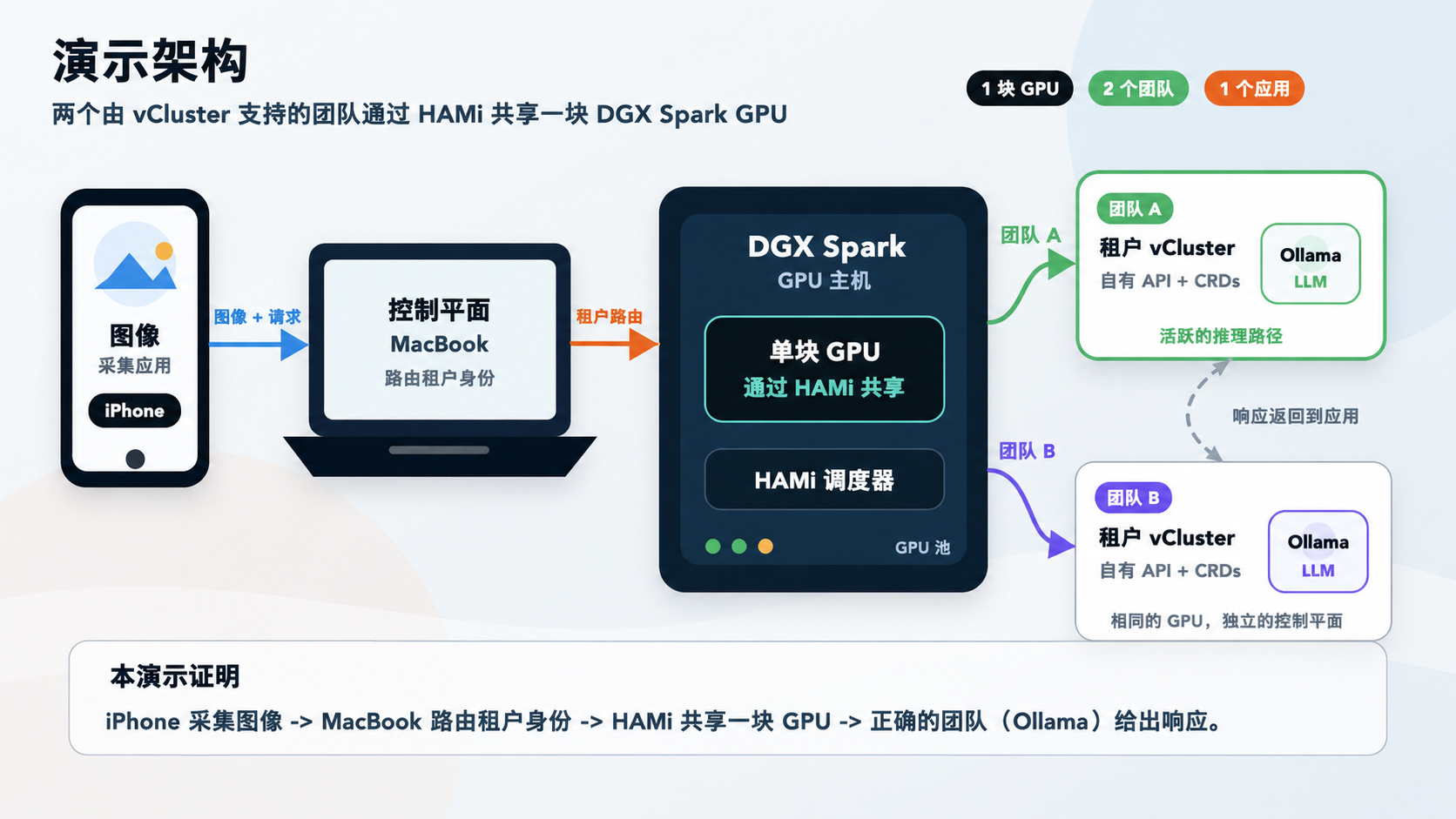
为了让概念更直观,演示使用了带�有孟买本地特色的应用场景,包括本地火车、dabbawala 送餐员和 kaali peeli 出租车。移动应用采集的图片会被路由到 Kubernetes,并交由运行在共享 GPU 基础设施上的 AI 模型完成推理。
这场 Keynote 并不只是解释 GPU 虚拟化概念,而是展示了多个独立 AI 团队如何共享同一张物理加速卡,同时保持彼此隔离的 Kubernetes 环境。
该演示说明,HAMi 与 vCluster 结合后,可以支撑资源高效、云原生的多租户 AI 平台。
展台现场演示
在 Project Pavilion,参观者体验了两场动手演示,展示 Kubernetes 上真实的 AI 推理场景。
如果你希望复现其中一部分 vLLM 工作流,可以参考 HAMi vLLM 实验。
Demo 1:基于 vLLM 与 SGLang 的生产级 AI 推理
第一场演示展示了在 Kubernetes 上使用 vLLM 和 SGLang 进行生产级 LLM serving,并由 HAMi 管理异构硬件上的 GPU 分配。演示使用了两种模型交付方式:直接从 Hugging Face 加载模型,以及通过 Kubernetes initContainers 分发 KitOps ModelKits 打包的模型,从而展示 AI 平台中灵活的部署策略。
推理栈运行在:
- Nebius 提供的 NVIDIA H100 GPU
- Reza Jelveh 提供的 NVIDIA A10 GPU
参观者可以看到:
- 生产级 LLM serving
- Kubernetes 原生部署工作流
- 感知资源的 GPU 调度
- �跨推理工作负载的高效 GPU 共享
- 通过现代推理引擎完成端到端请求路由
通过将 HAMi 与 vLLM、SGLang 等流行推理框架结合,这场演示展示了组织如何在提升 GPU 利用率的同时部署可扩展的 AI 服务。
Demo 2:动态 GPU 共享
第二场演示聚焦 HAMi 的 GPU 虚拟化能力。
参观者了解了多个 AI 工作负载如何通过显式资源控制共存于同一张物理 GPU 上,相关能力包括:
- 分数 GPU 分配
- 动态资源分配
- 灵活调度策略
- GPU 虚拟化
- Kubernetes 原生部署
参观者还通过 NVIDIA 工具验证资源分配情况,并实时观察推理请求如何流经共享基础设施。
这两场演示共同展示了 Kubernetes 如何从简单的 GPU 分配,进一步演进到面向现代 AI 平台的智能加速器调度。
展台交流
除演示之外,HAMi 展台也成为技术交流的中心,吸引了工程师、创业者、平台团队、CTO 以及正在探索 AI 基础设施的学生。
虽然参会者来自不同领域,但许多讨论都围绕同一个问题展开:
组织如何在更清晰的隔离和更可预测的工作负载放置基础上,共享昂贵的 GPU 资源?
HyperVerge:面向多租户 AI 的显存隔离
其中一次深入交流来自 HyperVerge。
他们的工程团队分享了此前使用 GPU 共享方案的经历:一些方案缺少推理工作负载之间清晰的 GPU 显存隔离控制。
对于在共享基础设施上服务多个客户的组织来说,这会带来显著的运维挑战。
这次讨论聚焦 HAMi 如何处理:
- GPU 显存隔离
- 智能调度
- Bin-packing 策略
- Spread 调度
- 多租户工作负载放置
对于企业级 AI 平台而言,将高效 GPU 利用率与更强的工作负载隔离控制结合起来,具有很高价值。
企业级调度讨论
来自 BlackRock 的工程师关注 HAMi 的调度算法,以及它如何在异构 GPU 工作负载之间做出放置决策。
类似地,InfraCloud 团队也讨论了 HAMi 如何集成到现有 Kubernetes 环境中,并对比了传统 Kubernetes Device Plugin、动态资源分配(DRA)和 HAMi 调度模型。
这些讨论反映了企业级 Kubernetes 平台中的一个更广泛趋势:
组织正在积极寻找更智能的方式,以消除 GPU 利用率不足问题,同时支持日益多样化的 AI 工作负载。
展台背后的社区

开源项目的成功离�不开社区。
感谢所有帮助 HAMi 展台顺利运行的人:
特别感谢 Jimmy Song 准备展台材料,并在整个活动期间支持社区。
展望
KubeCon India 期间的交流强化了一个清晰信号。
组织正在从传统的“每个团队一张 GPU”模式中走出来,积极寻找 Kubernetes 原生方案,以实现高效、可扩展、具备实际隔离控制的 GPU 共享。
随着 AI 基础设施持续演进,HAMi 这类技术将在帮助组织实现以下目标时发挥越来越重要的作用:
- 提升 GPU 利用率
- 降低基础设施成本
- 支撑多租户 AI 平台
- 在 Kubernetes 上部署生产级推理
- 更高效地扩展加速器基础设施
感谢每一位来到展台、参加 Keynote、提供反馈并贡献想法的朋友。
我们很高兴继续构建 Kubernetes GPU 基础设施的未来,也期待在下一届 KubeCon 再见。
