HAMi at KubeCon + CloudNativeCon India 2026: Bringing GPU Sharing to the Community
Held on June 18-19, 2026, in Mumbai, India, KubeCon + CloudNativeCon India 2026 brought together cloud native practitioners, platform engineers, AI infrastructure teams, and open source contributors from across the ecosystem. As AI emerged as one of the conference's defining themes, HAMi showcased how Kubernetes-native GPU sharing helps organizations maximize accelerator utilization while maintaining workload isolation and operational flexibility.
From the opening keynote to live booth demonstrations and technical discussions with engineering teams, the event highlighted a growing industry focus: making expensive GPU infrastructure practical for multi-tenant AI workloads.
AI Infrastructure Takes Center Stage
The conference opened with a strong focus on AI infrastructure. During the opening keynote, Chris Aniszczyk highlighted how cloud native technologies are becoming the foundation for the next generation of AI platforms.
HAMi's presence at KubeCon India built directly on that message by demonstrating how Kubernetes can share GPU resources across multiple teams and inference workloads without assigning a full GPU or a separate cluster to every workload.
Keynote Demo: Multi-Tenant AI Inference on Kubernetes

During Saiyam Pathak's keynote, HAMi powered a live demonstration showing GPU sharing in action.
The architecture combined:
- A MacBook running the Kubernetes control plane
- NVIDIA DGX Spark as the GPU worker
- vCluster for tenant isolation
- HAMi for fractional GPU allocation
- Multiple AI inference workloads running simultaneously on a shared GPU
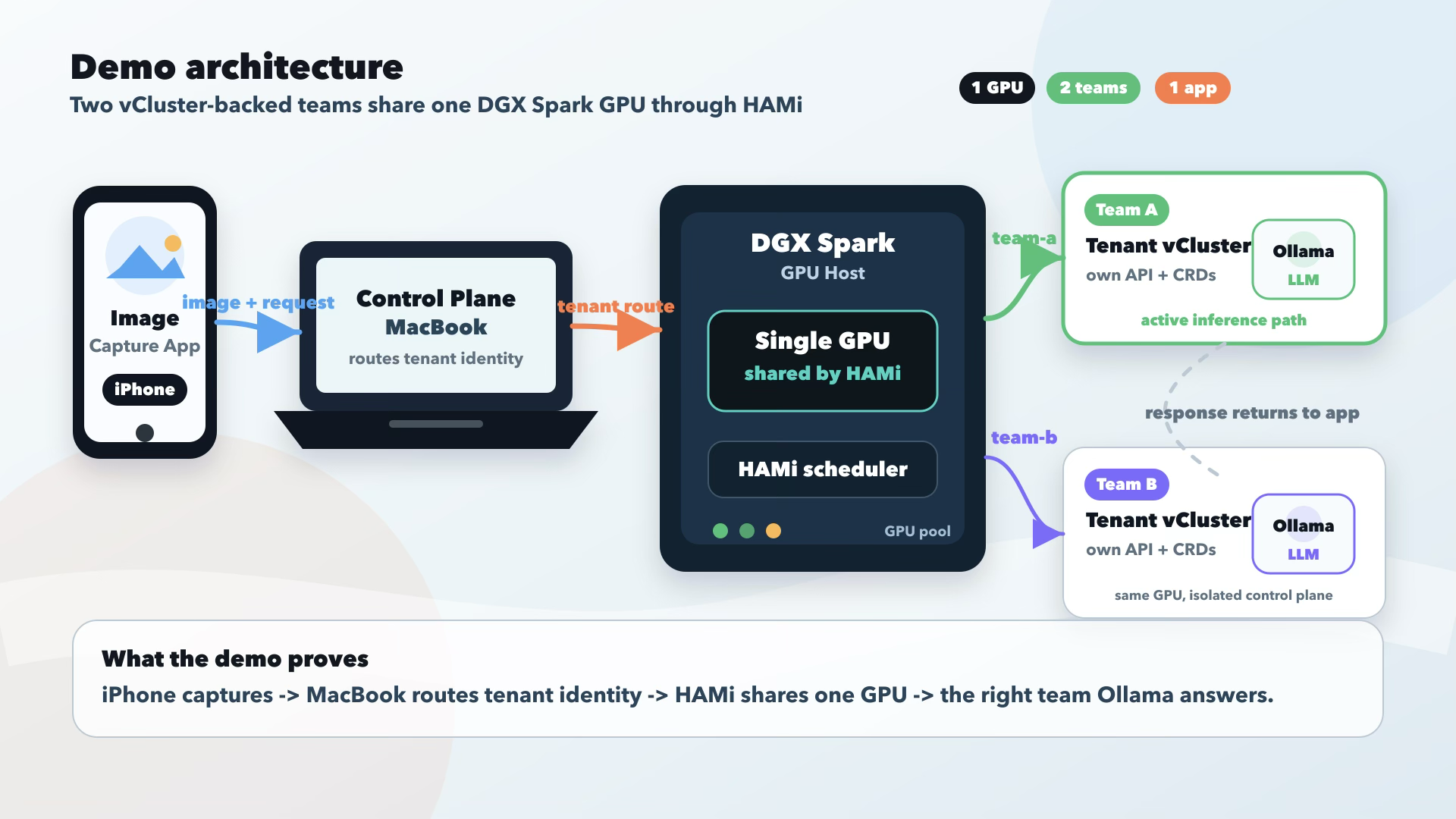
To make the concepts relatable, the demo used a Mumbai-themed application featuring local trains, dabbawalas, and kaali peeli taxis. Images captured on a mobile application were routed through Kubernetes to AI models running on the shared GPU infrastructure.
Rather than simply explaining GPU virtualization, the keynote demonstrated how multiple independent AI teams can share the same physical accelerator while maintaining isolated Kubernetes environments.
The demo illustrated how HAMi and vCluster together support practical multi-tenant AI platforms that are resource efficient and cloud native.
Live Booth Demonstrations
Throughout the Project Pavilion, visitors experienced two hands-on demonstrations highlighting real-world AI inference on Kubernetes.
For readers who want to reproduce parts of the vLLM workflow, see the HAMi vLLM lab.
Demo 1: Production AI Inference with vLLM and SGLang
The first demonstration showcased production-style LLM serving using vLLM and SGLang on Kubernetes, with HAMi managing GPU allocation across heterogeneous hardware. The demo used two model delivery approaches: serving models directly from Hugging Face, and packaging models with KitOps ModelKits delivered through Kubernetes initContainers, showing flexible deployment strategies for AI platforms.
The inference stack was deployed on:
- NVIDIA H100 GPUs provided by Nebius
- NVIDIA A10 GPUs provided by Reza Jelveh
Visitors could observe:
- Production-style LLM serving
- Kubernetes-native deployment workflows
- Resource-aware GPU scheduling
- Efficient GPU sharing across inference workloads
- End-to-end request routing through modern inference engines
By combining HAMi with popular inference frameworks such as vLLM and SGLang, the demo showed how organizations can deploy scalable AI services while improving GPU utilization.
Demo 2: Dynamic GPU Sharing
The second demonstration focused on HAMi's GPU virtualization capabilities.
Attendees explored how multiple AI workloads can coexist on the same physical GPU with explicit resource controls using:
- Fractional GPU allocation
- Dynamic resource assignment
- Flexible scheduling policies
- GPU virtualization
- Kubernetes-native deployment
Visitors also validated allocations using NVIDIA tooling while observing inference requests flowing through shared infrastructure in real time.
Together, both demonstrations showcased how Kubernetes can evolve beyond simple GPU allocation toward more intelligent accelerator scheduling for modern AI platforms.
Conversations from the Booth
Beyond the demonstrations, the booth became a hub for technical discussions with engineers, startup founders, platform teams, CTOs, and students exploring AI infrastructure.
Although attendees represented different industries, many conversations centered around the same challenge:
How can organizations share expensive GPU resources with clearer isolation and more predictable workload placement?
HyperVerge: Memory Isolation for Multi-Tenant AI
One of the most detailed discussions was with HyperVerge.
Their engineering team described previous experiences with GPU sharing solutions that lacked clear GPU memory isolation controls between inference workloads.
For organizations serving multiple customers on shared infrastructure, this presents significant operational challenges.
The discussion focused on how HAMi approaches:
- GPU memory isolation
- Intelligent scheduling
- Bin-packing strategies
- Spread scheduling
- Multi-tenant workload placement
The ability to combine efficient GPU utilization with stronger workload isolation controls was particularly valuable for enterprise AI platforms.
Enterprise Scheduling Discussions
Engineers from BlackRock were interested in HAMi's scheduling algorithms and how placement decisions are made across heterogeneous GPU workloads.
Similarly, the InfraCloud team discussed how HAMi integrates into existing Kubernetes environments while comparing traditional Kubernetes Device Plugins, Dynamic Resource Allocation (DRA), and HAMi's scheduling model.
These discussions reflected a broader trend across enterprise Kubernetes platforms:
Organizations are actively looking for smarter ways to eliminate GPU underutilization while supporting increasingly diverse AI workloads.
Community Behind the Booth

Open source projects succeed because of their communities.
A huge thank you to everyone who helped make the HAMi booth possible:
Special thanks to Jimmy Song for preparing booth materials and supporting the community throughout the event.
Looking Ahead
The conversations throughout KubeCon India reinforced a clear message.
Organizations are moving beyond the traditional "one GPU per team" model and are actively searching for Kubernetes-native solutions that enable efficient, scalable GPU sharing with practical isolation controls.
As AI infrastructure continues to evolve, technologies such as HAMi will play an increasingly important role in helping organizations:
- Increase GPU utilization
- Reduce infrastructure costs
- Support multi-tenant AI platforms
- Deploy production inference on Kubernetes
- Scale accelerator infrastructure more efficiently
Thank you to everyone who visited the booth, attended the keynote, shared feedback, and contributed ideas.
We're excited to continue building the future of GPU infrastructure for Kubernetes and we look forward to seeing you at the next KubeCon.
