版本:下一个
昆仑芯拓扑感知调度
背景
当单个 P800 服务器配置多块 XPU 时,若 GPU 连接或位于同一 NUMA 节点内(如下图所示),可获得最优性能表现。这种配置会在服务器内所有 GPU 之间形成特定拓扑关系。
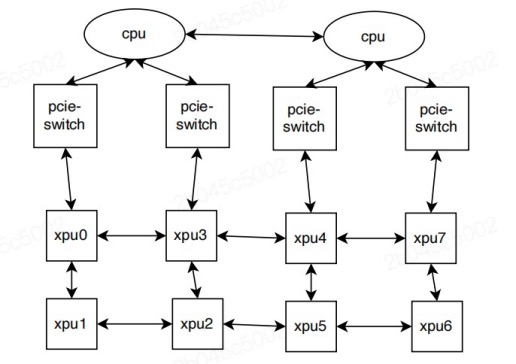
当用户作业申请特定数量的kunlunxin.com/xpu资源时,Kubernetes 会将 pod 调度到合适节点以最小化资源碎片并保持高性能。选定节点后,XPU 设备会根据以下规则进行细粒度资源分配:
- 仅允许 1、2、4 或 8 卡分配方案
- 1/2/4 卡分配不得跨 NUMA 节点
- 分配后应最小化资源碎片
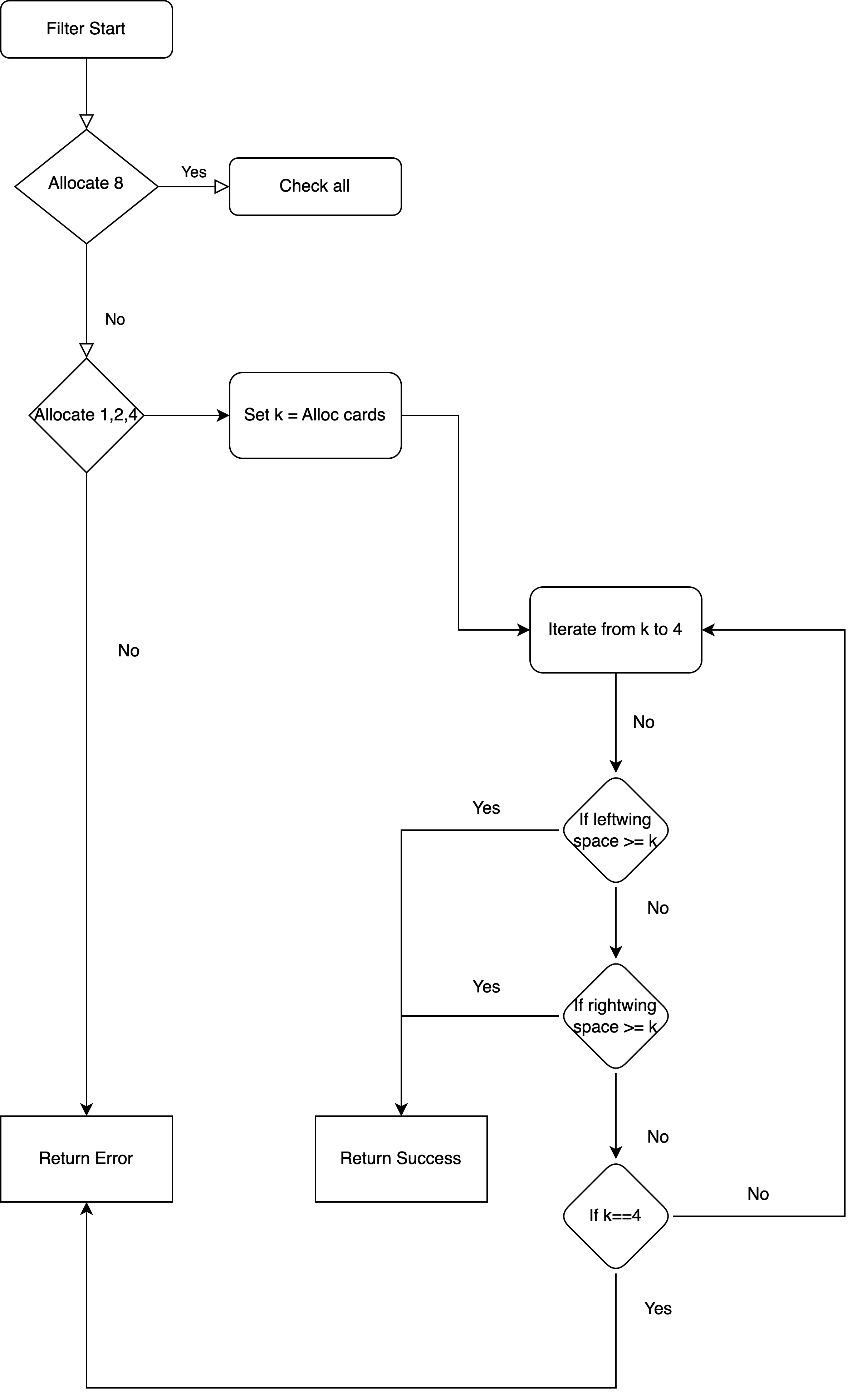
过滤阶段
过滤阶段识别所有符合分配条件的节点。针对每个节点,系统会筛选最优 XPU 组合方案并缓存,供评分阶段使用。筛选流程如下图所示:
评分阶段
在评分阶段,所有通过过滤的节点会接受评估并打分以选择最优调度目标。我们引入MTF(最小填充分任务数)指标,用于量化节点在分配后容纳未来任务的能力。
下表展示了 XPU 占用情况与对应 MTF 值的示例:
| XPU 占用状态 | MTF | 说明 |
|---|---|---|
| 11111111 | 0 | 完全占用,无法调度新任务 |
| 00000000 | 1 | 可被一个 8-XPU 任务完全占用 |
| 00000011 | 2 | 可调度一个 4-XPU 任务和一个 2-XPU 任务 |
| 00000001 | 3 | 可容纳一个 4-XPU、一个 2-XPU 和一个 1-XPU 任务 |
| 00010001 | 4 | 可容纳两个 2-XPU 任务和两个 1-XPU 任务 |
节点得分基于分配前后的MTF 差值计算。差值越小表示适配度越高,得分也越高。具体评分逻辑如下:
| MTF 差值 | 得分 | 示例 |
|---|---|---|
| -1 | 2000 | 00000111->00001111 |
| 0 | 1000 | 00000111->00110111 |
| 1 | 0 | 00001111->00011111 |
| 2 | -1000 | 00000000->00000001 |
绑定阶段
在绑定阶段,分配结果会以注解形式注入 pod。例如:
BAIDU_COM_DEVICE_IDX=0,1,2,3
