Scheduler Policy
Summary
Current in a cluster with many GPU nodes, nodes are not binpack or spread when making scheduling decisions, nor are GPU cards binpack or spread when using vGPU.
Proposal
The scheduler adds a node-scheduler-policy and gpu-scheduler-policy to config, then scheduler to use this policy can impl node binpack or spread or GPU binpack or spread or topology-aware. The topology-aware policy only takes effect with NVIDIA GPUs.
User can set Pod annotation to change this default policy, use hami.io/node-scheduler-policy and hami.io/gpu-scheduler-policy to overlay scheduler config.
User Stories
This is a GPU cluster, having two node, the following story takes this cluster as a prerequisite.
Story 1
node binpack, use one node’s GPU card whenever possible, egs:
-
cluster resources:
- node1: GPU having 4 GPU device
- node2: GPU having 4 GPU device
-
request:
- pod1: User 1 GPU
- pod2: User 1 GPU
-
scheduler result:
- pod1: scheduler to node1
- pod2: scheduler to node1
Story 2
node spread, use GPU cards from different nodes as much as possible, egs:
-
cluster resources:
- node1: GPU having 4 GPU device
- node2: GPU having 4 GPU device
-
request:
- pod1: User 1 GPU
- pod2: User 1 GPU
-
scheduler result:
- pod1: scheduler to node1
- pod2: scheduler to node2
Story 3
GPU binpack, use the same GPU card as much as possible, egs:
-
cluster resources:
- node1: GPU having 4 GPU device, they are GPU1,GPU2,GPU3,GPU4
-
request:
- pod1: User 1 GPU, gpucore is 20%, gpumem-percentage is 20%
- pod2: User 1 GPU, gpucore is 20%, gpumem-percentage is 20%
-
scheduler result:
- pod1: scheduler to node1, select GPU1 this device
- pod2: scheduler to node1, select GPU1 this device
Story 4
GPU spread, use different GPU cards when possible, egs:
-
cluster resources:
- node1: GPU having 4 GPU device, they are GPU1,GPU2,GPU3,GPU4
-
request:
- pod1: User 1 GPU, gpucore is 20%, gpumem-percentage is 20%
- pod2: User 1 GPU, gpucore is 20%, gpumem-percentage is 20%
-
scheduler result:
- pod1: scheduler to node1, select GPU1 this device
- pod2: scheduler to node1, select GPU2 this device
Design Details
Node-scheduler-policy
Binpack
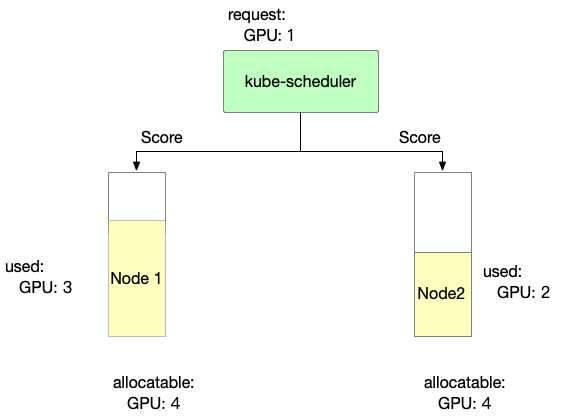
Binpack mainly considers node resource usage. The more full the usage, the higher the score.
score: ((request + used) / allocatable) * 10
- Binpack scoring information for Node 1 is as follows
Node1 score: ((1+3)/4) * 10= 10
- Binpack scoring information for Node 2 is as follows
Node2 score: ((1+2)/4) * 10= 7.5
So, in Binpack policy, the selected node is Node1.
Spread
Spread mainly considers node resource usage. The less it is used, the lower the score, but the higher the priority.
score: ((request + used) / allocatable) * 10
- Spread scoring information for Node 1 is as follows
Node1 score: ((1+3)/4) * 10= 10
- Spread scoring information for Node 2 is as follows
Node2 score: ((1+2)/4) * 10= 7.5
So, in Spread policy, the selected node is Node2.
GPU-scheduler-policy
Binpack
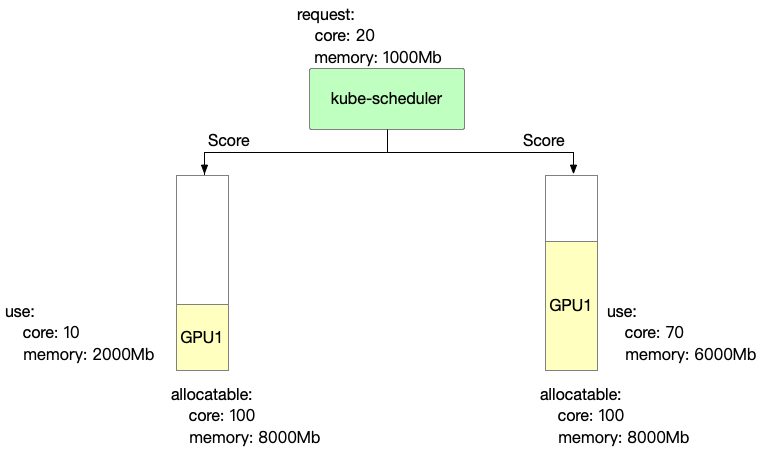
Binpack mainly focuses on the computing power and video memory usage of each card. The more it is used, the higher the score.
score: ((request.core + used.core) / allocatable.core + (request.mem + used.mem) / allocatable.mem)) * 10
- Binpack scoring information for GPU 1 is as follows
GPU1 Score: ((20+10)/100 + (1000+2000)/8000)) * 10 = 6.75
- Binpack scoring information for GPU 2 is as follows
GPU2 Score: ((20+70)/100 + (1000+6000)/8000)) * 10 = 17.75
So, in Binpack policy, the selected node is GPU2.
Spread
Spread mainly focuses on the computing power and video memory usage of each card. The less it is used, the higher the score.
score: ((request.core + used.core) / allocatable.core + (request.mem + used.mem) / allocatable.mem)) * 10
- Spread scoring information for GPU 1 is as follows
GPU1 Score: ((20+10)/100 + (1000+2000)/8000)) * 10 = 6.75
- Spread scoring information for GPU 2 is as follows
GPU2 Score: ((20+70)/100 + (1000+6000)/8000)) * 10 = 17.75
So, in Spread policy, the selected node is GPU1.
Topology-aware
NVIDIA Topology-aware (NVIDIA GPU Only)
NVIDIA Topology-aware primarily focuses on the topological relationships between each GPU (queried using the nvidia-smi topo -m command). The hami-device-plugin calculates scores between GPUs based on these relationships - the higher the bandwidth between GPUs, the higher the score. For example:
[
{
"uuid": "gpu0",
"score": {
"gpu1": "100",
"gpu2": "100",
"gpu3": "200"
}
},
{
"uuid": "gpu1",
"score": {
"gpu0": "100",
"gpu2": "200",
"gpu3": "100"
}
},
{
"uuid": "gpu2",
"score": {
"gpu0": "100",
"gpu1": "200",
"gpu3": "200"
}
},
{
"uuid": "gpu3",
"score": {
"gpu0": "200",
"gpu1": "100",
"gpu2": "200"
}
}
]
One GPU
When a Pod requests only one GPU, the GPU with the worst communication performance with other GPUs is prioritized - the lower the score, the higher the scheduling priority. For example:
- The sum of scores for gpu0 with other GPUs is as follows:
gpu0 score: 100 + 100 + 200 = 400
- The sum of scores for gpu1 with other GPUs is as follows:
gpu1 score: 100 + 200 + 100 = 400
- The sum of scores for gpu2 with other GPUs is as follows:
gpu2 score: 100 + 200 + 200 = 500
- The sum of scores for gpu3 with other GPUs is as follows:
gpu3 score: 200 + 100 + 200 = 500
Therefore, when a Pod requests only one GPU, the scheduler randomly selects either gpu0 or gpu1.
More than one GPU
When a Pod requests multiple GPUs (more than one), the combination with the highest score is prioritized - the higher the score, the higher the scheduling priority.
For example: If a Pod requests 3 GPUs, take gpu0, gpu1, gpu2 as an example. The score is calculated as:
totalScore = score(gpu0, gpu1) + score(gpu0, gpu2) + score(gpu1, gpu2)
- The score for gpu0, gpu1, gpu2 is as follows:
(gpu0, gpu1, gpu2) totalScore: 100 + 100 + 200 = 400
- The score for gpu0, gpu1, gpu3 is as follows:
(gpu0, gpu1, gpu3) totalScore: 100 + 200 + 100 = 400
- The score for gpu1, gpu2, gpu3 is as follows:
(gpu1, gpu2, gpu3) totalScore: 200 + 100 + 200 = 500
Therefore, when a Pod requests 3 GPUs, the scheduler allocates gpu1, gpu2, gpu3.
